



在讲解基础的排序算法之前,先来介绍排序算法经常会用到的 `swap` 函数——用来交换列表中的两项的位置
1 | def swap(lyst, i, j): |
选择排序 | \(selection \, sort\)
可能最简单的策略就是搜索整个列表,找到最小项的位置。如果该位置不是列表的第一个位置,算法就会交换这两个位置的项。然后,算法回到第 2 个位置并且重复这个过程,如果必要的话,将最小项和第 2 个位置的项交换。当算法到达整个过程的最后一个位置,列表就是排序好的了。这就是选择排序算法的基本思路。
下表展示了对于 5 个项的一个列表进行选择排序,在每一次搜索和交换之后的状态。因为每次经过主循环时,都会选择一个要移动的项,即在每一轮都只是交换两项,这两项的后面用 * 表示,并且表中已经排好序的部分用阴影表示。
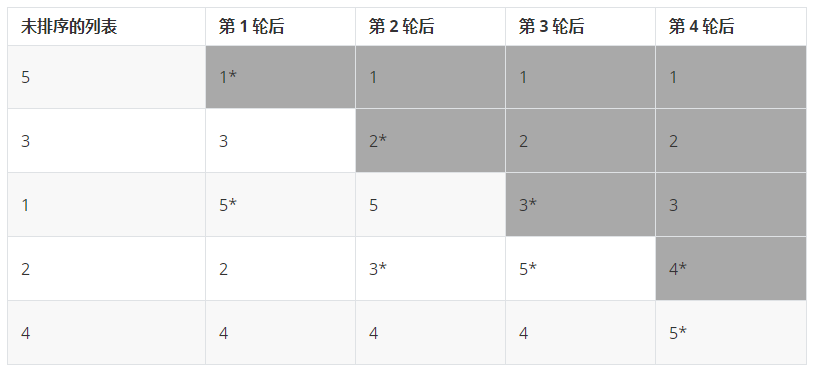
如下是选择排序的 Python 描述:
1 | def selectionSort(lyst): |
该算法的复杂度为 `O(n^2)`。由于数据项交换只是在外围循环中进行,所以在最坏情况和平均情况下,选择排序的这一额外开销都是线性的。
冒泡排序 | \(bubble \,sort\)
冒泡排序法相对容易理解和编码。其策略是从列表的开头出开始,并且比较一对数据项,直到移动到列表的末尾。每当成对的两项之间顺序不正确的时候,算法就交换其位置。这个过程的效果就是将最大的项以冒泡的方式排到列表的末尾。然后,算法从列表头到倒数第 2 个列表项重复这一过程,依此类推,直到该算法从列表的最后一项开始执行。此时,列表是已经排序好的。
下表展示了对 5 个项的一个列表进行冒泡排序的过程。这个过程把嵌套的循环执行了 4 次,将最大的项冒泡的列表的末尾。再一次,只有交换的项用*标出,并且排好序的部分用阴影表示。
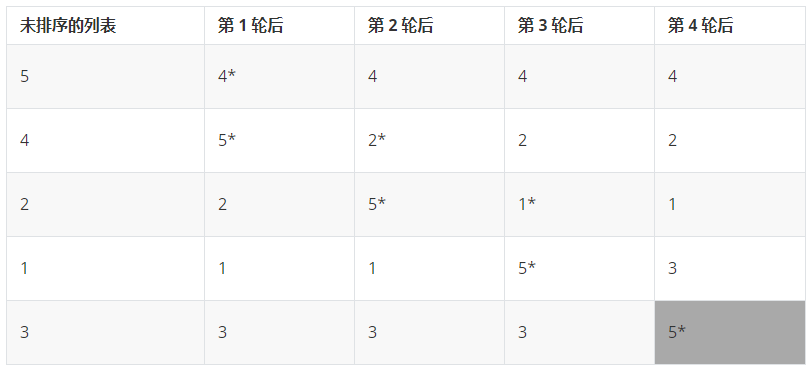
如下是冒泡排序的 Python 描述:
1 | def bubbleSort(lyst): |
和选择排序一样,冒泡排序的复杂度也是 `O(n^2)`。如果列表是已经排好的,冒泡排序不会执行任何交换。然而,在最坏的情况下,冒泡排序的交换超过线性方式。
可以对冒泡排序进行一个小的调整,将其在最好的情况下的性能提高到线性阶。如果在通过主循环的时候,没有发生交换,那么列表就是已经排序的。这种情况可能发生在任何一轮,但是,在最好的情况下,第 1 轮就会发生。可以使用一个布尔标记来记录交换动作的出现,并且当内部循环没有设置这个标记的时候,就从函数返回。如下是修改后的冒泡排序函数:
1 | def bubbleSortWithTweak(lyst): |
注意:这一修改只是改进了最好情况下的行为。在平均情况下,这个版本的复杂度仍为`O(n^2)`。
插入排序 | \(insertion \,sort\)
修改过后的冒泡排序,对于已经排好的列表来说,其性能比选择排序要好。但是,如果列表中的项是没有顺序的,修改过后的冒泡排序的性能任然是很糟糕的。
插入排序法试图以一种不同的方式来对列表进行排列,其策略如下:
在第 i 轮通过列表的时候(\( 1 \leq i \leq n-1 \)),第 i 个项应该插入到列表的前 i 个项之中的正确位置。
在第 i 轮之后,前 i 个项应该是排好序的。
这个过程类似于排列手中扑克牌的顺序。即,如果你按照顺序放好了前 i-1 张牌,抓取了第 i 张牌,并且将其与手中的牌进行比较,直到找到合适的位置。
和其他排序算法一样,插入排序包含两个循环。外围的循环遍历从 1 到 n-1 的位置。对于这个循环中的每一个位置 i, 我们都保存该项并且从位置 i-1 开始内部循环。对于这个循环中的每一个位置 j,我们都将项移动到位置 j+1,直到找到了给保存的项(第 i 项)的插入位置。
如下是 insertionSort 函数的代码:
1 | def insertionSort(lyst): |
下表展示了对 5 个项的一个列表进行插入排序,以及在每一次通过外围循环后的状态。在下一个轮次中插入的项用一个箭头标记出来,在将这个项插入之后,用*将其标记。
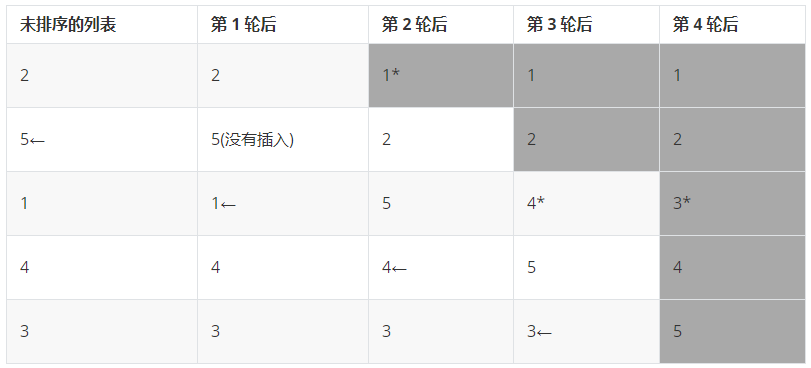
插入排序的最坏情况的复杂的为 `O(n^2)`。列表中排好序的项越多,插入排序的效果越好,在最好的情况下,列表本来就是有序的,那么,插入排序的复杂度是线性阶的。然而,在平均情况下,插入排序的复杂度仍然是二次方阶的。



