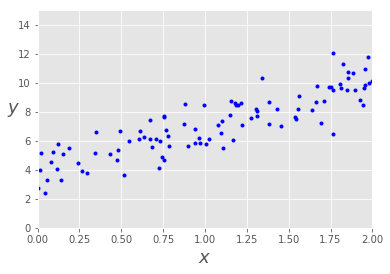
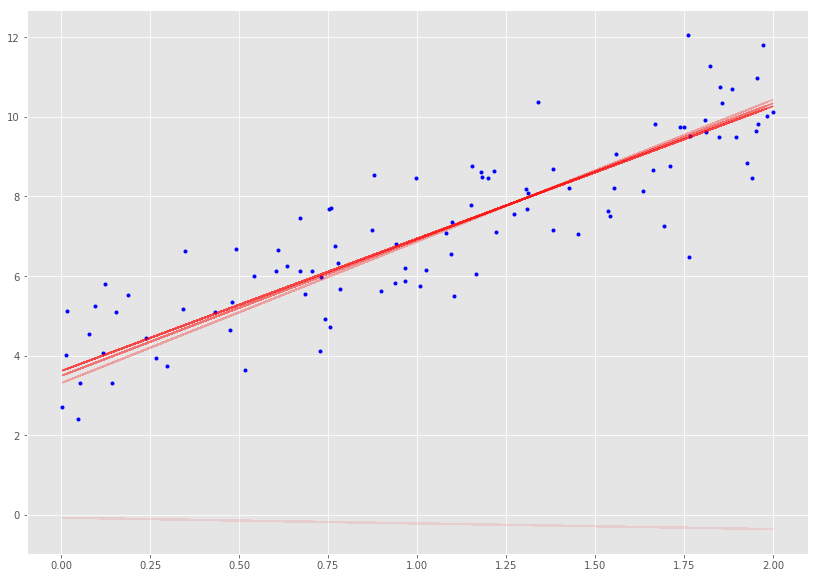
defcal_cost(theta, X, y): ''' Calculates the cost for given X and Y. The following shows and example of a single dimensional X theta = Vector of thetas X = Row of X's np.zeros((2,j)) y = Actual y's np.zeros((2,1)) where: j is the no of features ''' m = len(y) predictions = X.dot(theta) cost = (1/2*m) * np.sum(np.square(predictions - y)) return cost
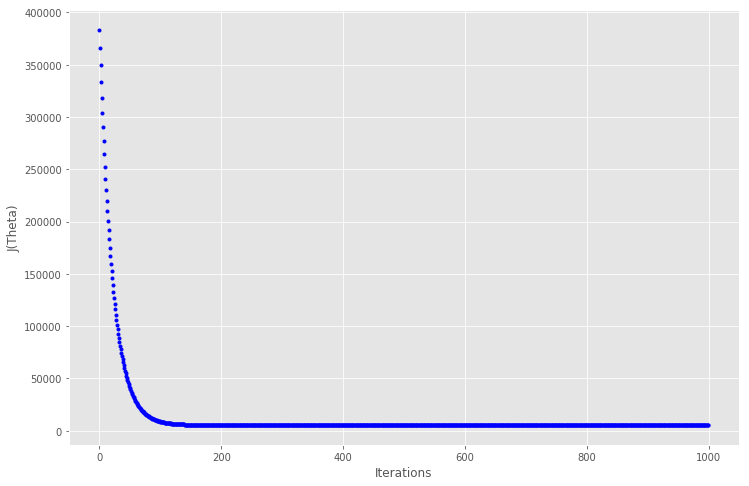
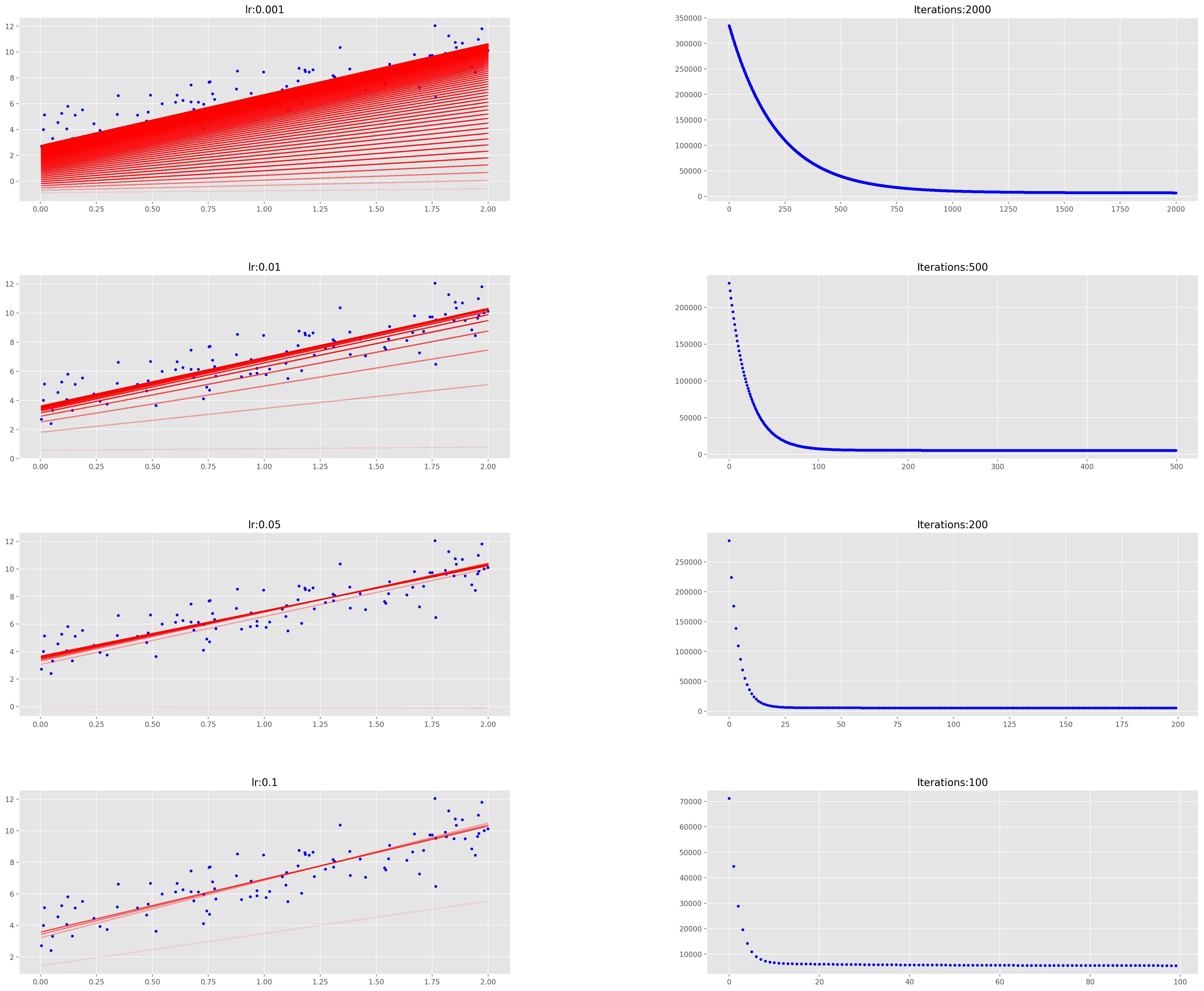
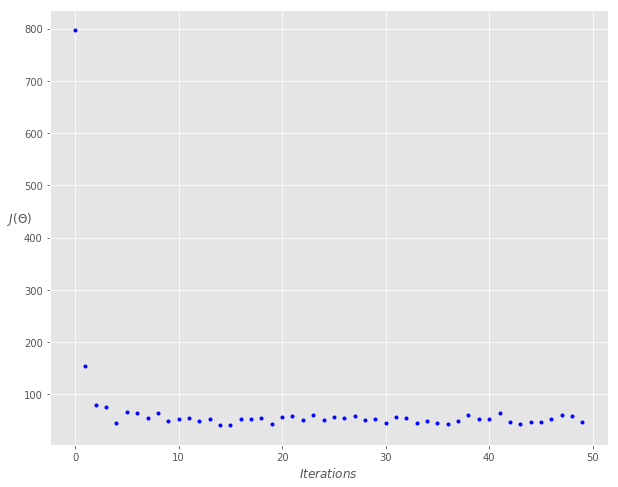
defgradient_descent(X, y, theta, learning_rate = 0.01, iterations = 100): ''' X = Matrix of X with added bias units y = Vector of Y theta=Vector of thetas np.random.randn(j,1) learning_rate iterations = no of iterations Returns the final theta vector and array of cost history over no of iterations ''' m = len(y) # learning_rate = 0.01 # iterations = 100 cost_history = np.zeros(iterations) theta_history = np.zeros((iterations, 2)) for i in range(iterations): prediction = np.dot(X, theta) theta = theta - (1/m) * learning_rate * (X.T.dot((prediction - y))) theta_history[i, :] = theta.T cost_history[i] = cal_cost(theta, X, y) return theta, cost_history, theta_history
defstocashtic_gradient_descent(X, y, theta, learning_rate=0.01, iterations=10): ''' X = Matrix of X with added bias units y = Vector of Y theta=Vector of thetas np.random.randn(j,1) learning_rate iterations = no of iterations Returns the final theta vector and array of cost history over no of iterations ''' m = len(y) cost_history = np.zeros(iterations) for it in range(iterations): cost = 0.0 for i in range(m): rand_ind = np.random.randint(0, m) X_i = X[rand_ind, :].reshape(1, X.shape[1]) y_i = y[rand_ind, :].reshape(1, 1) prediction = np.dot(X_i, theta) theta -= (1/m) * learning_rate * (X_i.T.dot((prediction - y_i))) cost += cal_cost(theta, X_i, y_i) cost_history[it] = cost return theta, cost_history
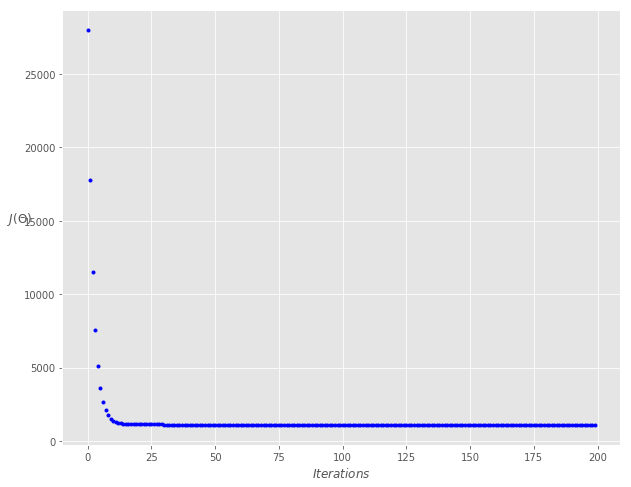
defminibatch_gradient_descent(X, y, theta, learning_rate=0.01, iterations=10, batch_size=20): ''' X = Matrix of X without added bias units y = Vector of Y theta=Vector of thetas np.random.randn(j,1) learning_rate iterations = no of iterations Returns the final theta vector and array of cost history over no of iterations ''' m = len(y) cost_history = np.zeros(iterations) n_batches = int(m / batch_size) for it in range(iterations): cost = 0.0 indices = np.random.permutation(m) X = X[indices] y = y[indices] for i in range(0, m, batch_size): X_i = X[i: i+batch_size] y_i = y[i: i+batch_size] X_i = np.c_[np.ones(len(X_i)), X_i] prediction = np.dot(X_i, theta) theta -= (1/m) * learning_rate * (X_i.T.dot((prediction - y_i))) cost += cal_cost(theta, X_i, y_i) cost_history[it] = cost return theta, cost_history
1 2 3 4 5 6 7
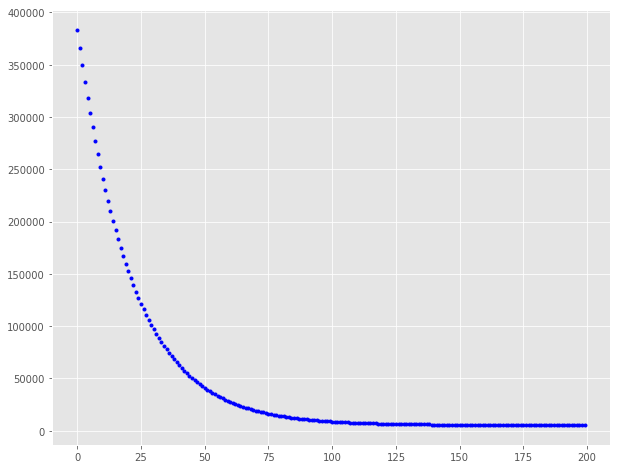
lr = 0.1 n_iter = 200 theta = np.random.randn(2, 1) theta, cost_history = minibatch_gradient_descent(X, y, theta, lr, n_iter)