



划分聚类,顾名思义,通过划分的方式将数据集划分为多个不重叠的子集(簇),每一个子集作为一个聚类(类别)。
在划分的过程中,首先由用户确定划分子集的个数 `k`,然后随机选定 `k` 个点作为每一个子集的中心点,接下来通过迭代的方式:计算数据集中每个点与各个中心点之间的距离,更新中心点的位置;最终将数据集划分为 `k` 个子集,即将数据划分为 `k` 类。
而评估划分的好坏标准就是:保证同一划分的样本之间的差异尽可能的小,且不同划分中的样本差异尽可能的大。
K-Means 聚类方法
在划分聚类中,K-Means 是最具有代表性的算法,下面用图片的方式演示 K-Means 的基本算法流程。希望大家能通过简单的图文演示,对 K-Means 方法的原理过程产生大致的印象。
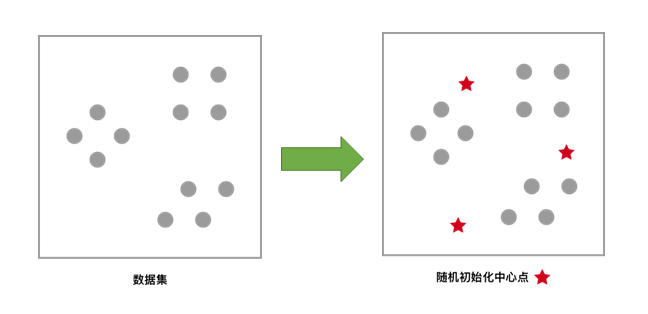
[1] 对于未聚类数据集,首先随机初始化 K 个(代表拟聚类簇个数)中心点,如图红色五角星所示。
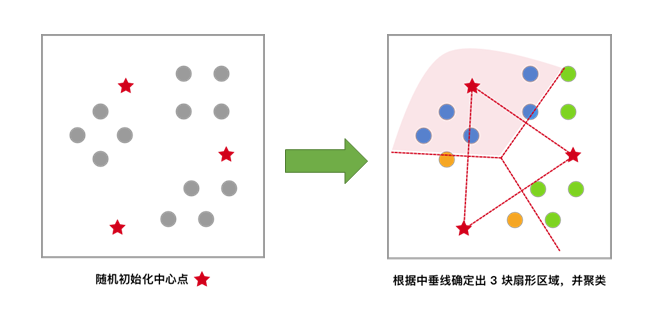
[2] 每一个样本按照距离自身最近的中心点进行聚类,等效于通过两中心点连线的中垂线划分区域。
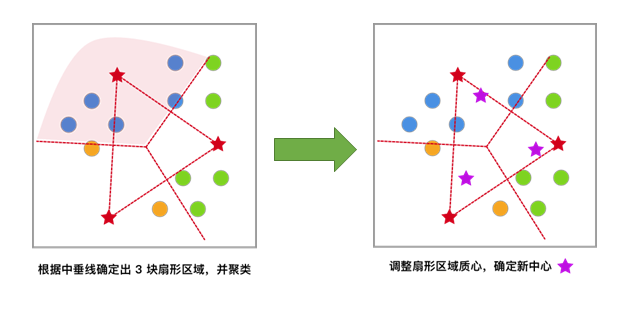
[3] 依据上次聚类结果,移动中心点到个簇的质心位置,并将此质心作为新的中心点
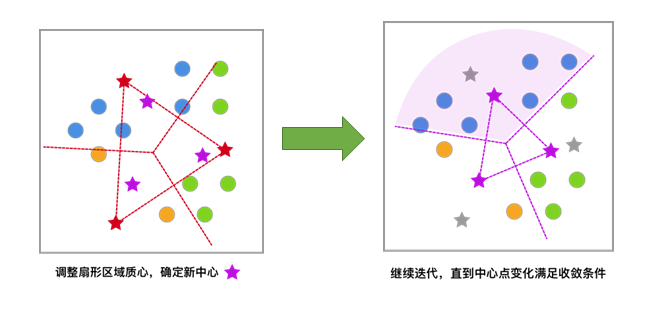
[4] 反复迭代,直至中心点的变化满足收敛条件(变化很小或几乎不变化),最终得到聚类结果。
在对 K-Means 有了一个直观了解后,下面我们用 Python 来进行实现。
生成示例数据
首先通过 scikit-learn 模块的 make_blobs() 函数生成本次实验所需的示例数据。该方法可以按照我们的要求,生成特定的团状数据。
1 | data,label = sklearn.datasets.make_blobs(n_samples=100,n_features=2,centers=3,center_box=(-10.0,10.0),random_state=None) |
其中参数为:
n_samples:表示生成数据总个数,默认为 100 个。n_features:表示每一个样本的特征个数,默认为 2 个。centers:表示中心点的个数,默认为 3 个。center_box:表示每一个中心的边界,默认为 -10.0到10.0。random_state:表示生成数据的随机数种子。
返回值为:
data:表示数据信息。label:表示数据类别。
根据上面函数,在 0.0 到 10.0 上生成 200 条数据,大致包含 3 个中心。由于是用于演示聚类效果,数据标签就不是必须的了,在生成数据时赋值给 _,后面也不会使用到。
1 | """构造数据 |
array([[ 8.28390539, 4.98011149],
[ 7.05638504, 7.00948082],
[ 7.43101466, -6.56941148],
[ 8.20192526, -6.4442691 ],
[ 3.15614247, 0.46193832],
[ 7.7037692 , 6.14317389],
[ 5.62705611, -0.35067953],
[ 7.53828533, -4.86595492],
[ 8.649291 , 3.98488194],
[ 7.91651636, 4.54935348]])
数据可视化
为了更加直观的查看数据分布情况,使用 matplotlib 将生成数据绘画出来。
1 | """数据展示 |
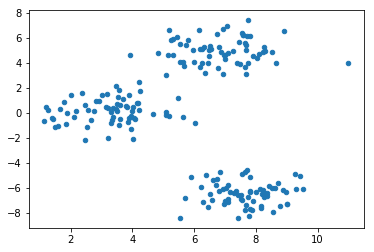
随机初始化中心点
当我们得到数据时,依照划分聚类方法的思想,首先需要随机选取 `k` 个点作为每一个子集的中心点。从图像中,通过肉眼很容易的发现该数据集有 3 个子集。接下来,用 numpy 模块随机生成 3 个中心点,为了更方便展示,这里我们加入了随机数种子以便每一次运行结果相同。
1 | """初始化中心点 |
array([[ 6.42802708, -1.51776689],
[ 3.09537831, 1.97999275],
[ 1.11702824, -0.27169709]])
在随机生成好中心点之后,将其在图像中表示出来,这里同样使用红色五角星表示。
1 | """初始中心点展示 |
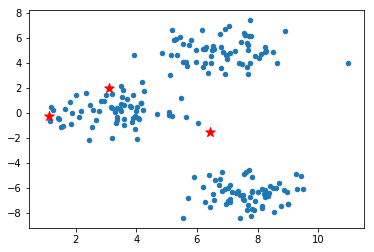
计算样本与中心点的距离
为了找到最合适的中心点位置,需要计算每一个样本和中心点的距离,从而根据距离更新中心点位置。常见的距离计算方法有欧几里得距离和余弦相似度,本实验采用更常见且更易于理解的欧几里得距离(欧式距离)。
欧式距离源自 `N` 维欧氏空间中两点之间的距离公式。表达式如下:
$$
d_{euc}= \sqrt{\sum_{i=1}^{N}(X_{i}-Y_{i})^{2}} \tag{1}
$$
其中:
- `X`, `Y` :两个数据点
- `N`:每个数据中有 `N` 个特征值,
- `X_{i}` :数据 `X` 的第 `i` 个特征值
将两个数据 `X` 和 `Y` 中的每一个对应的特征值之间差值的平方,再求和,最后开平方,便是欧式距离。
1 | """计算欧氏距离 |
最小化 SSE,更新聚类中心
和第一章的回归算法通过减小目标函数(如:损失函数)的值拟合数据集一样,聚类算法通常也是优化一个目标函数,从而提高聚类的质量。在聚类算法中,常常使用误差的平方和 SSE(Sum of squared errors)作为度量聚类效果的标准,当 SSE 越小表示聚类效果越好。其中 SSE 表示为:
$$
SSE(C)=\sum_{k=1}^{K}\sum_{x_{i}\in C_{k}}\left | x_{i}-c_{k} \right |^{2} \tag{2}
$$
其中数据集 \(D=\{ x_{1},x_{2},…,x_{n} \}\),\(x_{i}\)表示每一个样本值,`C` 表示通过 K-Means 聚类分析后的产生类别集合 \(C=\{ C_{1},C_{2},…,C_{K} \}\) ,\(c_{k}\) 是类别 \(C_{k}\) 的中心点,其中 \(c_{k}\) 计算方式为:
$$
c_{k}=\frac{\sum_{x_{i} \in C_{k}}x_{i}}{I(C_{k})} \tag{3}
$$
\(I(C_{k})\) 表示在第 `k` 个集合 \(C_{k}\) 中数据的个数。
当然,我们希望同最小化损失函数一样,最小化 SSE 函数,从而找出最优化的聚类模型,但是求其最小值并不容易,是一个 NP 难(非确定性多项式)的问题,其中 NP 难问题是一个经典图论问题,至今也没有找到一个完美且有效的算法。
下面我们对中心点的更新用代码的方式进行实现:
1 | """中心点的更新 |
K-Means 聚类算法实现
K-Means 算法则采用的是迭代算法,避开优化 SSE 函数,通过不断移动中心点的距离,最终达到聚类的效果。
算法流程
- 初始化中心点:判断数据集可能被分为 `k` 个子集,随机生成 `k` 个随机点作为每一个子集的中心点。
- 距离计算,类别标记:样本和每一个中心点进行距离计算,将距离最近的中心点所代表的类别标记为该样本的类别。
- 中心点位置更新:计算每一个类别中的所有样本的均值,作为新的中心点位置。
- 重复 2,3 步骤,直到中心点位置不再变化。
算法实现
1 | """K-Means 聚类 |
完成 K-Means 聚类函数后,接下来用函数得到最终中心点的位置。
1 | """计算最终中心点 |
array([[ 7.67007252, -6.44697348],
[ 6.83832746, 4.98604668],
[ 3.28477676, 0.15456871]])
最后,我们把聚类得到的中心绘制到原图中看一看聚类效果。
1 | """可视化展示 |
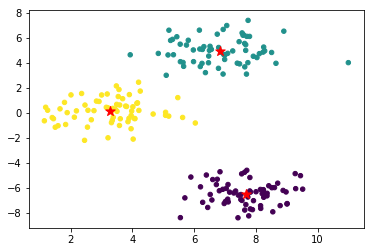
中心点移动过程可视化
截止上小节,已经完成了 K-Means 聚类的流程。为了帮助大家理解,我们尝试将 K-Means 聚类过程中,中心点移动变化的过程绘制出来。
1 | num_axes = len(centers_container) |
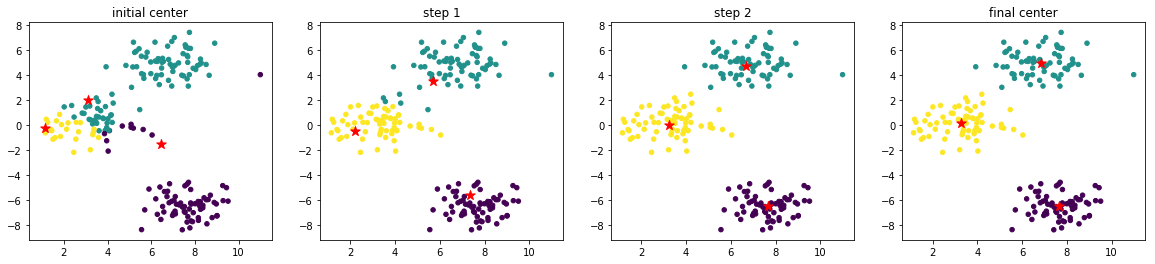
你会惊讶的发现,对于示例数据集,虽然我们先前将最大迭代次数 max_step 设为了 50,但实际上 K-Means 迭代 3 次即收敛。原因主要有 2 点:
- 初始化中心点的位置很好,比较均匀分布在了数据范围中。如果初始化中心点集中分布在某一角落,迭代次数肯定会增加。
- 示例数据分布规整和简单,使得无需迭代多次就能收敛。
K-Means 算法聚类中的 K 值选择
不知道你是否还记得,前面在学习分类算法 K-近邻的时候,我们讲到了 K 值的选择。而在使用 K-Means 算法聚类时,由于要提前确定随机初始化中心点的数量,同样面临着 K 值选择问题。
在前面寻找 K 值时,我们通过肉眼观察认为应该聚为 3 类。那么,如果我们设定聚类为 5 类呢?
这一次,我们尝试通过 scikit-learn 模块中的 K-Means 算法完成聚类。
1 | from sklearn.cluster import k_means |
其中参数为:
X:表示需要聚类的数据。n_clusters:表示聚类的个数,也就是 K 值。
返回值包含:
centroid:表示中心点坐标。label:表示聚类后每一个样本的类别。inertia:每一个样本与最近中心点距离的平方和,即 SSE。
1 | """用 scikit-learn 聚类并绘图 |
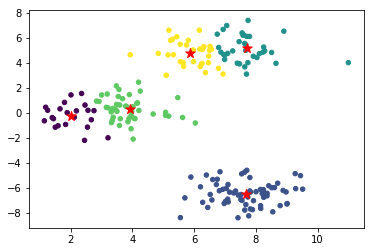
从图片上来看,聚为 5 类效果明显不如聚为 3 类的好。当然,我们提前用肉眼就能看出数据大致为 3 团。
实际的应用过程中,如果通过肉眼无法判断数据应该聚为几类?或者是高维数据无法可视化展示。面对这样的情况,我们就要从数值计算的角度去判断 K 值的大小。
接下来,将介绍一种启发式学习算法,被称之为 肘部法则,可以帮助我们选取 K 值。
使用 K-Means 算法聚类时,我们可以计算出按不同 K 值聚类后,每一个样本距离最近中心点距离的平方和 SSE。
随着 K 值增加时,也就是类别增加时,每个类别中的类内相似性也随之增加,由此造成的 SSE 的变化是单调减小的。可以想象一下,聚类类别的数量和样本的总数相同时,也就是说一个样本就代表一个类别时,这个数值会变成 0。
下面我们通过代码将不同的数量的聚类下,样本和最近中心点的距离和绘制出来。
1 | index = [] # 横坐标数组 |
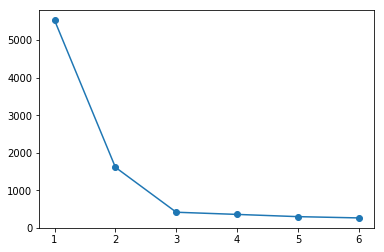
通过上图可以看到,和预想的一样,样本距离最近中心点距离的总和会随着 K 值的增大而降低。
现在,回想本实验划分聚类中所讲评估划分的好坏标准:「保证同一划分的样本之间的差异尽可能的小,且不同划分中的样本差异尽可能的大」。
当 K 值越大时,越满足「同一划分的样本之间的差异尽可能的小」。而当 K 值越小时,越满足「不同划分中的样本差异尽可能的大畸变程度最大」。那么如何做到两端的平衡呢?
于是,我们通过 SSE 所绘制出来的图,将畸变程度最大的点称之为「肘部」。从图中可以看到,这里的「肘部」是 K = 3(内角最小,弯曲度最大)。这也说明,将样本聚为 3 类是最佳选择(K = 2 比较接近)。这就是所谓的「肘部法则」,你明白了吗?
K-Means++ 聚类算法
问题引入
随着数据量的增长,分类数目增多时,由于 K-Means 中初始化中心点是随机的,常常会出现:一个较大子集有多个中心点,而其他多个较小子集公用一个中心点的问题。即算法陷入局部最优解而不是达到全局最优解的问题。
造成这种问题主要原因就是:一部分中心点在初始化时离的太近。下面我们通过例子来进一步了解。
生成示例数据
同样,我们先使用 scikit-learn 模块的 make_blobs 函数生成本次实验所需数据,本次生成 800 条数据,共 5 堆。
1 | """生成数据并展示 |
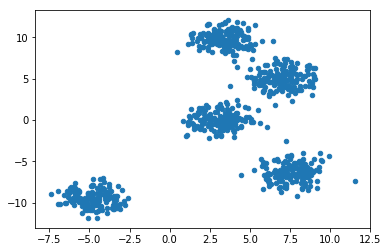
随机初始化中心点
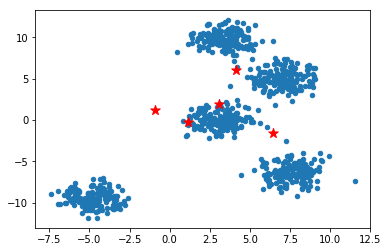
从数据点分布中可以很容易的观测出聚类数量应该为 5 类,我们先用 K-Means 中随机初始中心点的方法完成聚类:
1 | km_init_center=random_k(5, blobs_plus) |
K-Means 聚类
用传统的 K-Means 算法,将数据集进行聚类,聚类数量为 5。
1 | km_centers, km_clusters = kmeans_cluster(blobs_plus, km_init_center, 5) |
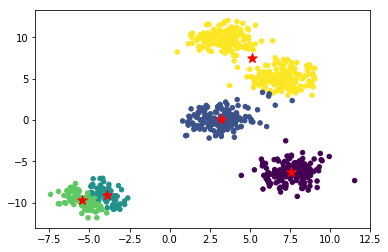
通过传统 K-Means 算法聚类后,你会发现聚类效果和我们预想不同,我们预想的结果应该是下面这样的:
1 | plt.scatter(blobs_plus[:, 0], blobs_plus[:, 1], s=20, c=_) |
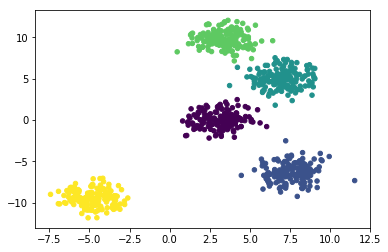
对比 K-Means 聚类和预想聚类的两张图,可以直观的看出 K-Means 算法显然没有达到最优的聚类效果,出现了本章开头所提到的局部最优解的问题。
对于局部最优问题是可以通过 SSE 来解决的,即在同一数据集上运行多次 K-Means 算法聚类,之后选取 SSE 最小的那次作为最终的聚类结果。虽然通过 SSE 找到最优解十分困难,但通过 SSE 判断最优解是十分容易的。
但当遇到更大的数据集,每一次 K-Means 算法会花费大量时间时,如果使用多次运行通过 SSE 来判断最优解,显然不是好的选择。是否有一种方法在初始化中心点时,就能有效避免局部最优问题的出现呢?
在 K-Means 的基础上,D.Arthur 等人在 2007 年提出了 K-Means++ 算法。其中 K-Means++ 算法主要针对初始化中心点问题进行改进,这样就可以从源头上解决局部最优解的问题。
K-Means++ 算法流程
K-Means++ 相较于 K-Means 在初始化中心点上做了改进,在其他方面和 K-Means 相同。
- 在数据集中随机选择一个样本点作为第一个初始化的聚类中心。
- 计算样本中的非中心点与最近中心点之间的距离 `D(x)` 并保存于一个数组里,将数组中的这些距离加起来得到 \(Sum(D(x))\)。
- 取一个落在 \(Sum(D(x))\)范围中的随机值 `R` ,重复计算 \(R=R-D(x)\) 直至得到 \(R\leq0\) ,选取此时的点作为下一个中心点。
- 重复 2,3 步骤,直到 `K` 个聚类中心都被确定。
- 对 `K` 个初始化的聚类中心,利用 K-Means 算法计算最终的聚类中心。
看完整个算法流程,可能会出现一个疑问:为避免初始点距离太近,直接选取距离最远的点不就好了,为什么要引入一个随机值 `R` 呢?
其实当采用直接选取距离最远的点作为初始点的方法,会容易受到数据集中离群点的干扰。采用引入随机值 `R` 的方法避免数据集中所包含的离群点对算法思想中要选择相距最远的中心点的目标干扰。
相对于正常的数据点,离群点所计算得出的 `D(x)` 距离一定比较大,这样在选取的过程中,它被选中的概率也就相对较大,但是离群点在整个数据集中只占一小部分,大部分依然是正常的点,这样离群点由于距离大而造成的概率大,就被正常点的数量大给平衡掉。从而保证了整个算法的平衡性。
K-Means++ 算法实现
K-Means++ 在初始化样本点之后,计算其他样本与其最近的中心点距离之和,以备下一个中心点的选择,下面用 Python 来进行实现:
1 | def get_sum_dis(centers, data): |
接下来,我们初始化中心点:
1 | """K-Means++ 初始化中心点 |
实现 K-Means++ 初始化中心点函数之后,根据生成数据,得到初始化的中心点坐标。
1 | plus_init_center = get_init_center(blobs_plus, 5) |
array([[ 4.1661903 , 0.81807492],
[ 8.9161603 , 5.58757202],
[ 7.62699601, 2.3492678 ],
[-3.42049424, -9.57117787],
[ 3.35681598, -0.54000802]])
为了让你更清晰的看到 K-Means++ 初始化中心点的过程,我们用 matplotlib 进行展示。
1 | num = len(plus_init_center) |

通过上图可以看到点的变化,即除了最初随机选择点之外,之后的每一个点都是尽可能选择远一些的点。这样就很好的保证初始中心点的分散。
通过多次执行代码可以看到,使用 K-Means++ 同样可能出现两个中心点较近的情况,因此,在极端情况也可能出现局部最优的问题。但相比于 K-Means 算法的随机选取,K-Means++ 的初始化中心点会在很大程度上降低局部最优问题出现的概率。
在通过 K-Means++ 算法初始化中心点后,下面我们通过 K-Means 算法对数据进行聚类。
1 | plus_centers, plus_clusters = kmeans_cluster(blobs_plus, plus_init_center, 5) |
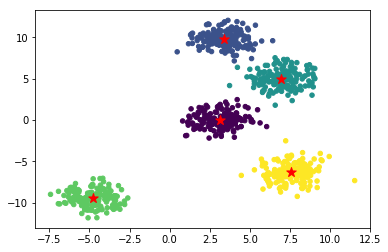
在 K-Means++ 算法中,我们依旧无法完全避免随机选择中心点带来的不稳定性,所以偶尔也会得到不太好的结果。当然,K-Means++ 算法得到不太好的聚类的概率远小于 K-Means 算法。所以,如果你并没有得到一个较好的聚类效果,可以再次初始化中心点尝试。
Mini-Batch K-Means 聚类算法
在「大数据」如此火的时代,K-Means 算法是否还能一如既往优秀的处理大数据呢?现在我们重新回顾下 K-Means 的算法原理:首先,计算每一个样本同所有中心点的距离,通过比较找到最近的中心点,将距离最近中心点的距离进行存储并归类。然后通过相同类别样本的特征值,更新中心点的位置。至此完成一次迭代,经过多次迭代后最终进行聚类。
通过上面的表述,你是否感觉到不断计算距离的过程,涉及到的计算量有多大呢?那么,设想一下数据量达到十万,百万,千万级别,且如果每一条数据有上百个特征,这将会消耗大量的计算资源。
为了解决大规模数据的聚类问题,我们就可以使用 K-Means 的另外一个变种 Mini Batch K-Means 来完成。
其算法原理也十分简单:在每一次迭代过程中,从数据集中随机抽取一部分数据形成小批量数据集,用该部分数据集进行距离计算和中心点的更新。由于每一次都是随机抽取,所以每一次抽取的数据能很好的表现原本数据集的特性。
下面,我们生成一组测试数据,并测试 K-Means 算法和 Mini Batch K-Means 在同一组数据上聚类时间和 SSE 上的差异。由于 scikit-learn 中 MiniBatchKMeans() 和 KMeans() 方法的参数几乎一致,这里就不再赘述了。
1 | import time |
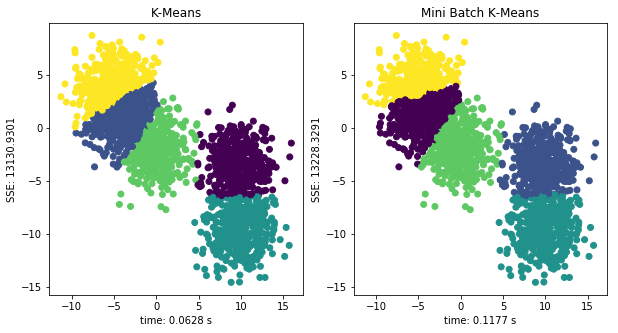
以上是对 2000 条数据分别用 K-Means 和 Mini Batch K-Means进行聚类,从图像中可以看出,Mini Batch K-Means 在训练时间上明显比 K-Means 快(大于 2 倍不等),且聚类得到的 SSE 值比较接近。
拓展阅读:



